【簡易版】AI音声認識による日本語発音テストツールを作ってみた

みなさん、こんにちは!バイタリフィアジアのNiheiです。普段は、生成AIを活用したプロダクト開発をアドバイスしたり、プロジェクトマネージャー (PM / PMO) として様々な開発PJをご支援しております。
今回は、外国人の方の日本語力をちょっと簡単に使ってみるだけで判定できるツールを作ってみました。といっても、ネイティブな日本語力を目指すための第一歩として、発音や抑揚がどれだけ近いかな?というのをチェックする仕組みを入れています。
概要
このツールでは、ユーザーが録音した音声と、あらかじめ用意してある「ネイティブの音声(参照音声)」を比較します。主にやっているのは以下の2つです:
- 録音した音声と参照音声の基本周波数(F0)の違いをチェックして、“話し方の抑揚” が似ているかどうかを数値化。
- 録音した音声から音声認識を使って文字を取り出し、正解のテキストと比べてどれだけ一致しているかを計算。
こうすることで、「イントネーションはネイティブっぽいけど、単語はちょっと違うかも」「文字はほぼ完璧だけど、抑揚がまだぎこちないかも」みたいな分析が一目でわかります。
本編
実際の動きとしては、このような流れになっています。
- 録音: 読み上げるテキストが表示されているため、それを読み上げます。ボタンを押すと、マイクから音声を録音します。録音が終わると、ツールの中に音声データが保存されます。

- 読み上げた後に、「類似度分析」ボタンを押します。

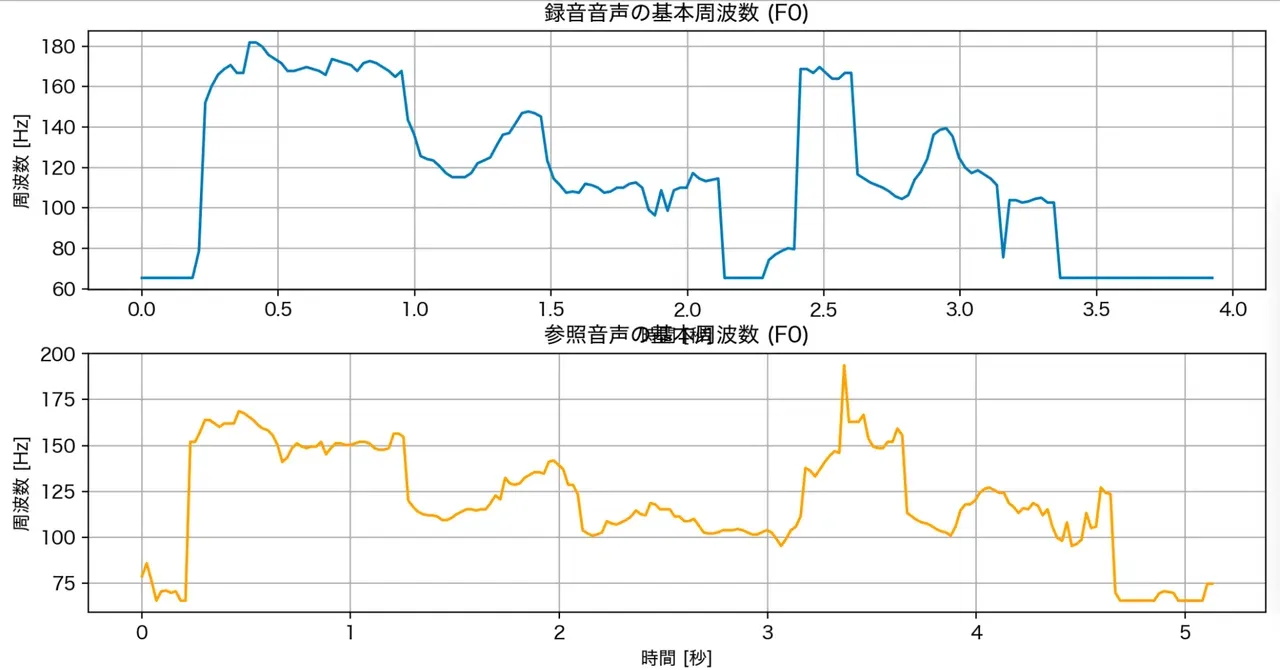
- 音声の分析: その音声から基本周波数(F0)を抽出して、どんな抑揚かを数値データにします。
- 参照音声との比較: ネイティブの発音と録音した発音を比べると「どれだけ似ているのか」を計算できます。動的時間伸縮(DTW)という手法で、長さが違う音声でもうまく比較できます。

上記のようなグラフが表示されました。予め録音しておいた参照音声と、いま録音をした音声との一致率の比較を行った結果、0.83 ( 83% ) と表示されました。
- 文字起こし&照合: Whisperなどの音声認識を使って、録音した音声を文字にします。そして、正解テキストとどれだけ一字一句そろっているかをチェックすることで、“正確さ” を数値化します。

上記のように、参照音声を文字起こししてひらがなにした文章と、いま録音した音声を文字起こししてひらがなにした文章の文字の一致率を比較した結果、テキスト一致率は、0.97 ( 97% ) でした。
- 結果の表示: 最後に、似ている度合いや文字の一致率をグラフや数値で見られるようになっています。これを見れば、録音した日本語の発音や一位率がどんな状態かざっくり把握できます。

まとめ
このツールの仕組みを応用すると、日本語を話す外国人人材の日本語力のレベル感がわかりやすくなるほか、「もうちょっとイントネーションをこう直せばいいのかも」「ここは正しい単語だけど発音が惜しい!」なんて気づきが得られます。学習者の方だけでなく、外国人スタッフの日本語力をざっくりチェックしたい企業さんにも役立つかもしれません。
もし「うちでも使ってみたい!」「どうやってカスタマイズできるの?」など、気になることがありましたら、お気軽にお問い合わせください。みなさんのお仕事や学習に、少しでもお役に立てれば嬉しいです。
「Generative AI & ML」の関連記事

Function Callingとは?AIエージェントの仕組みとLangGraph実装
LLMに外部ツールを操作させる「Function Calling」とは?自律型AIエージェントの進化の歴史から、LangGraph(TypeScript)を用いた自社専用エージェントの具体的な実装コードまで徹底解説。

夜空の星を解きほぐす:GNNと記号的AIでノイズ点群から星座を復元!ハイブリッドモデル開発
ノイズだらけの点群から星座を正確に検出!GNN(グラフニューラルネットワーク)と記号的AIを組み合わせた、高精度なハイブリッド・パターン認識手法の構築プロセスを解説します。
ノイズだらけの物件図面を推論し3Dモデルを自動生成!CubiCasa5K解析とリバースエンジニアリングの挑戦
ノイズだらけの物件間取り図(CubiCasa5K)から、機械学習で3Dモデルを自動生成!論文も既存コードも一切見ない「リバースエンジニアリング縛り」で挑む、最高に泥臭くて学びのあるAI開発の全記録。