画像1枚から3Dを作る技術 - Zero123からUnique3Dまでの進化の過程を解説


「たった1枚のイラストや写真から、ぐるりと見渡せる3Dモデルが自動でできたら……」
少し前まで、3Dモデルを作るにはBlenderやMayaといった専門ソフトを使い、職人が手作業で何日もかけて形を作り込むのが当たり前でした。
しかし今、AIの進化によってその常識が覆ろうとしています。
Image-to-3D や Generative 3D と呼ばれる分野では、まるで魔法のように2D画像から立体を生み出す技術が次々と発表されています。
この記事では、この革命的な進化の歴史において重要なバトンを繋いできた5つの技術、「Zero123」「MVDream」「SV3D」「Era3D」「Unique3D」について、それぞれの仕組みと進化の物語を丁寧に解説します。
誤解されがちな「画像から3D」の本当の仕組み
解説に入る前に、とても重要な事実をお伝えします。
実は、これから紹介するAI技術の多くは、直接「3Dモデル(ポリゴンの塊)」を作っているわけではありません。
現在のGenerative 3Dの主流は、大きく分けて2つのステップの連携プレイで行われています。
- AIの役割(多視点画像の生成): 「正面」の画像を見たAIが、自分が学習してきた知識を総動員して、「横から見たらこうなるはず」「後ろはこうだろう」と予測し、いろんな角度から見た画像(多視点画像)を描き出します。
- 3D化プログラムの役割(3D構築): AIが描いた複数の視点の画像(図面のようなもの)をコンピューター上で計算し、「どの角度から見ても辻褄が合う立体」として、実際の3Dメッシュ(ポリゴン)に組み立てます。
ここから紹介する技術たちは、主に「ステップ1」において、いかに矛盾のない、正確な別角度の図面(画像)をAIに描かせるかという難題に立ち向かってきました。
全ての基礎を築いた偉大な先駆者:「Zero123」
まず紹介すべきは、2023年春に発表されたZero123です。
これは、Stable Diffusionのような画像生成AIを応用した、画期的なブレイクスルーでした。
 cvlab-columbia
cvlab-columbiaこがスゴイ!:見えない裏側を1枚ずつ「想像」する
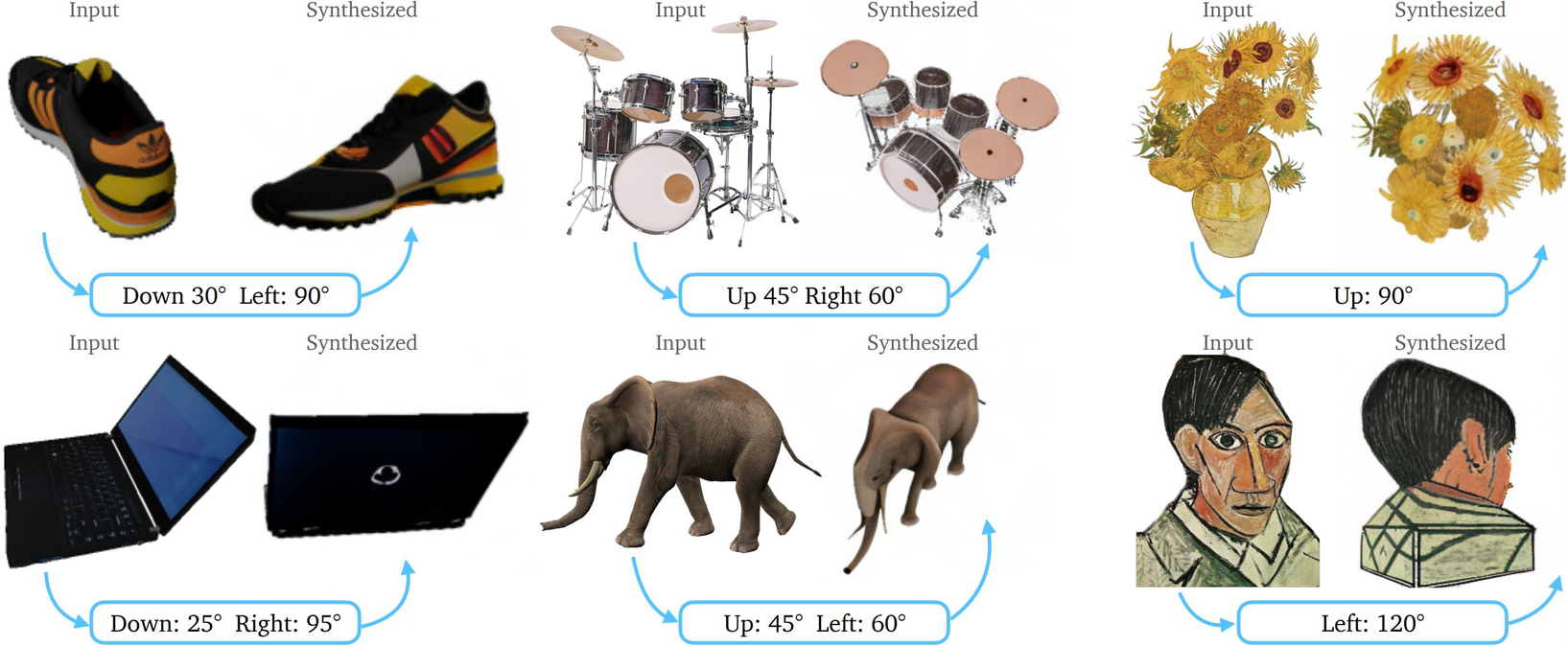
Zero123の凄さは、「1枚の画像」と「カメラを動かしたい角度(例:右に30度)」を入力すると、指定した角度から見た新しい画像を1枚生成できたことです。
これ以前は、3Dモデルを作るために実物を様々な角度から撮影した大量の写真が必要でした。しかしZero123は、AIの「想像力」を使うことで、1枚の画像から見えない裏側を予測して描き出すことを可能にしました。
残された課題:恐ろしい「ヤヌス問題」
しかし、Zero123には弱点がありました。
「指定した角度の画像を1枚ずつバラバラに生成する」という仕組みだったため、正面の画像と横の画像で服のデザインが変わってしまったり、最悪の場合、「後ろから見た画像にも顔がある(ヤヌス問題)」というような、矛盾した画像が生まれることが多かったのです。これでは、次の「3D構築(ステップ2)」の際に破綻してしまいます。
矛盾のない多視点生成への大きな一歩:「MVDream」
Zero123が抱えていた「生成するたびに形が変わってしまう」という問題を解決するために登場したのが、MVDreamです。
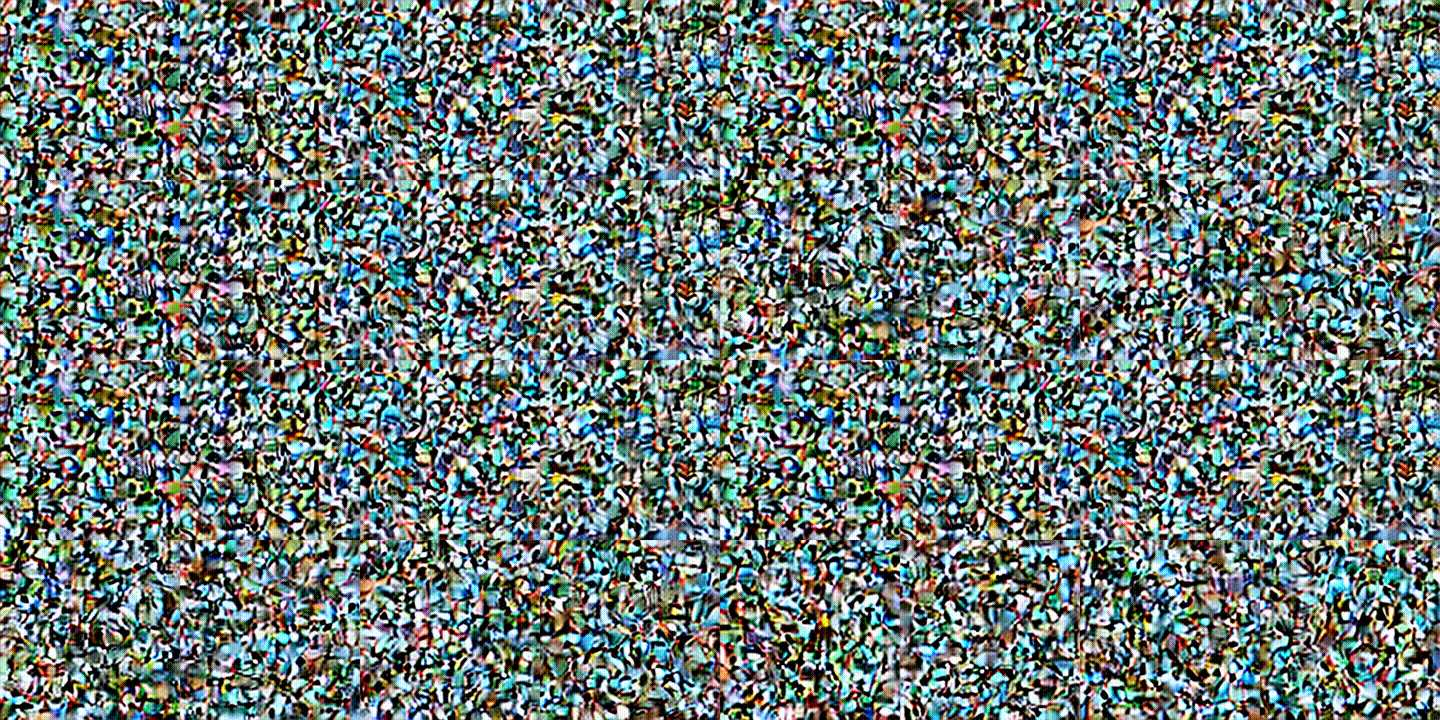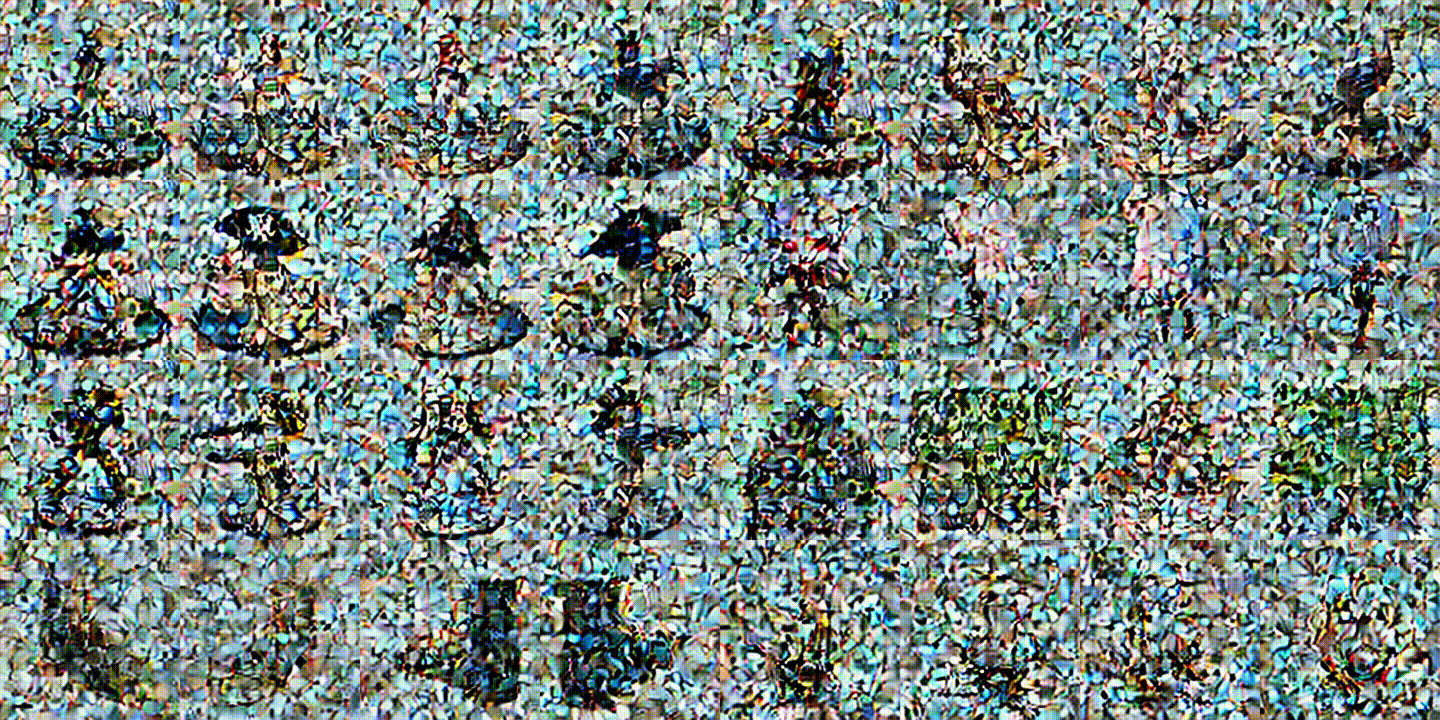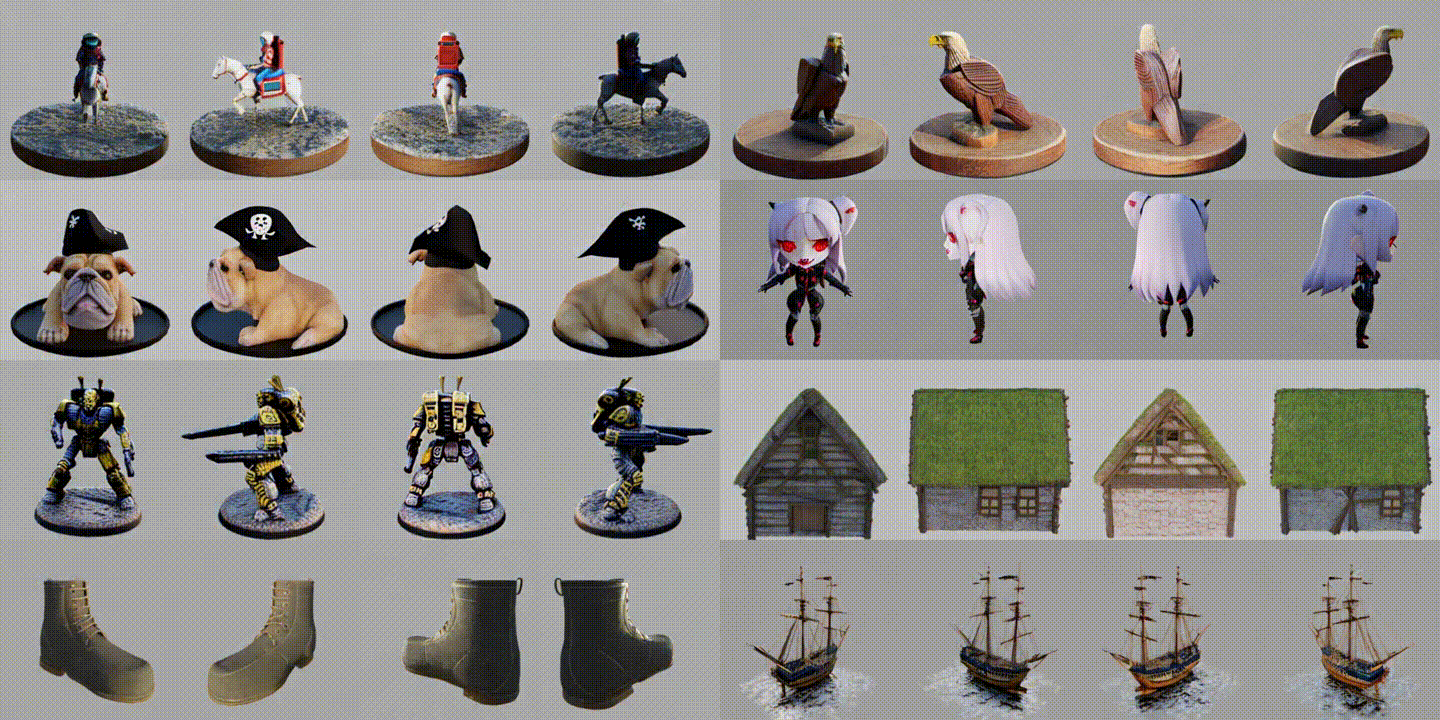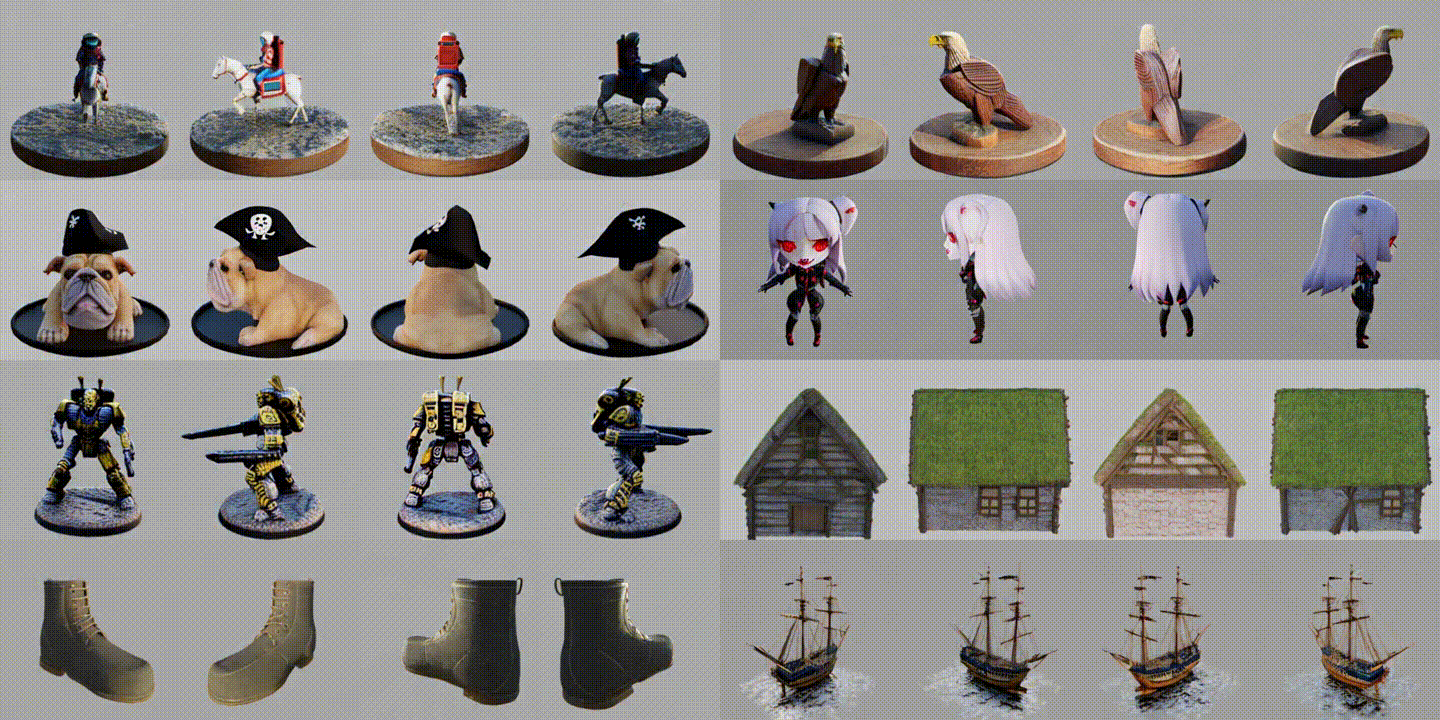
ここがスゴイ!:前後左右を「同時に」描くから辻褄が合う
MVDreamは、正面、右、左、後ろの4つの視点の画像を「同時に」生成するというアプローチ(Multi-view Diffusion)を取りました。
福笑いを想像してみてください。バラバラに顔のパーツを置くと変な顔になりますが、全体を見ながら同時に配置すれば正しい顔になりますよね。
MVDreamのAIも、4つの視点全体を把握しながら同時に画像を描き出すため、前後左右の辻褄が完璧に合った、一貫性のある多視点画像を出力できるようになりました。これにより、ステップ2の3D構築が劇的に成功しやすくなったのです。
「動画」の力で滑らかな3Dの一貫性を極める:「SV3D」
2024年にStability AIから発表されたSV3D (Stable Video 3D) は、MVDreamとはまた少し違った、ユニークなアプローチを取りました。


ここがスゴイ!:物体の周りをカメラが一周する「動画」を作る
SV3Dは、「動画生成AI」をベースの技術にしています。AIに「物体をぐるりと一周見回す動画」を生成させたのです。
動画生成AIは、「前のコマと次のコマが滑らかに繋がる」ことを得意としています。どこから見ても破綻のない数十枚の滑らかな連番画像(動画)が生成できるということは、MVDreamの4枚の画像よりも、はるかに密度の高い「正確な3D情報(図面)」を得られることを意味します。
騙し絵からの脱却!物理的に正しい凹凸データを予測:「Era3D」
技術が進むにつれ、全体のシルエットは綺麗に生成できるようになってきました。
しかし、AIが描いた画像を元に3Dモデル化すると、「のっぺりしている」という新たな課題がありました。表面の細かな凹凸(服のシワや鎧の模様など)を正確に表現するのが難しかったのです。
そこで登場したのがEra3Dです。

ここがスゴイ!:色付き画像だけでなく「法線マップ」も生成する
従来のAIは、画像に直接「影」を描き込むことで立体的に見せる「騙し絵」のようなことをしがちでした。
これに対しEra3Dは、色付きの別角度画像だけでなく、「法線マップ(Normal Map)」と呼ばれるデータを同時に生成します。法線マップとは、表面の細かい向き(ここが出っ張っている、へこんでいる)を表す特殊な画像データです。
Era3Dは、色情報だけでなく物理的な「凹凸情報」もAIに予測させることで、ステップ2で3Dモデル化する際のディテールの精度を飛躍的に高めることに成功しました。
高品質な「使える3D出力」までを統合:「Unique3D」
最後は、これまでの技術の集大成とも言えるUnique3D(2024年発表)です。
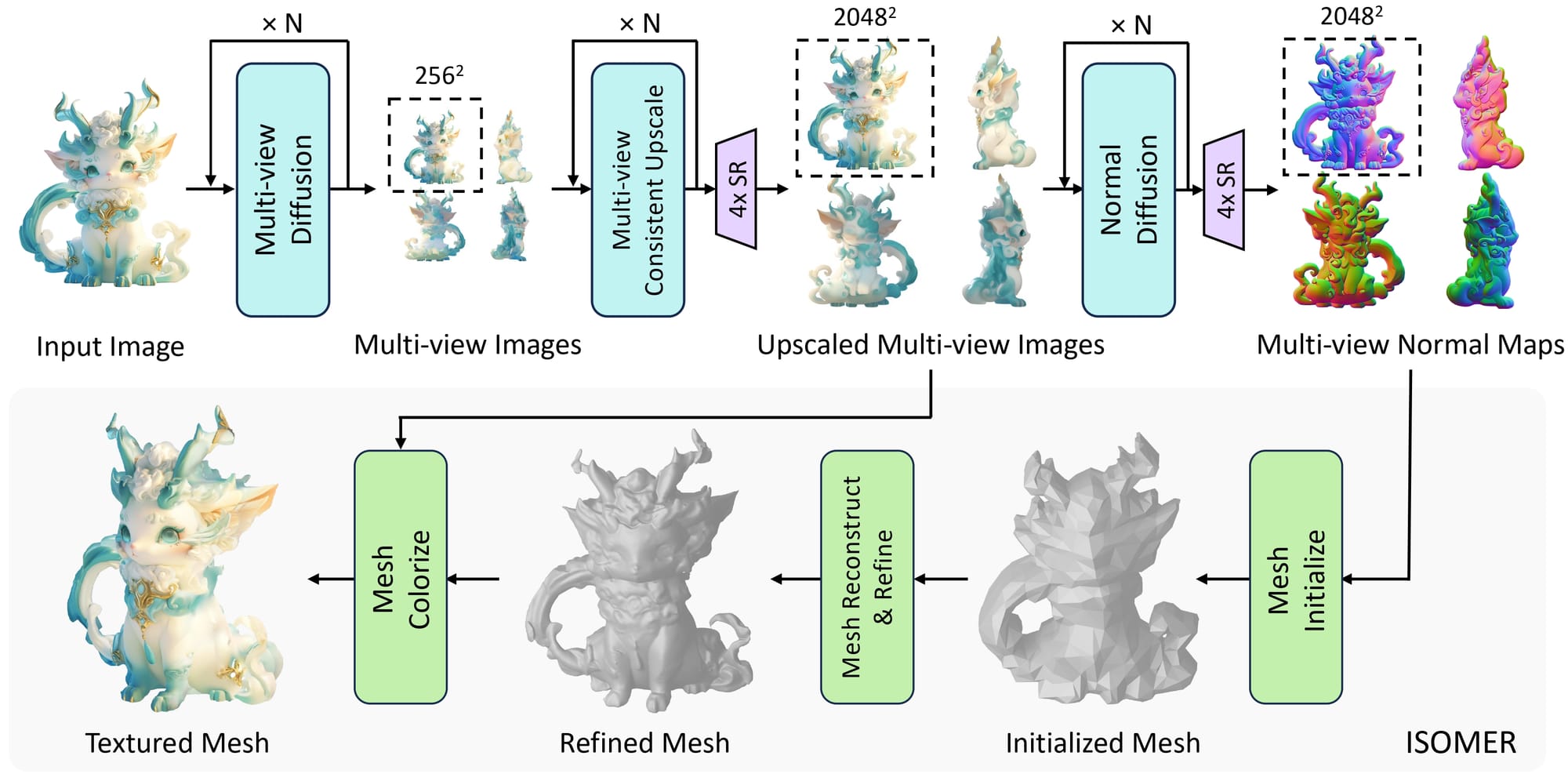
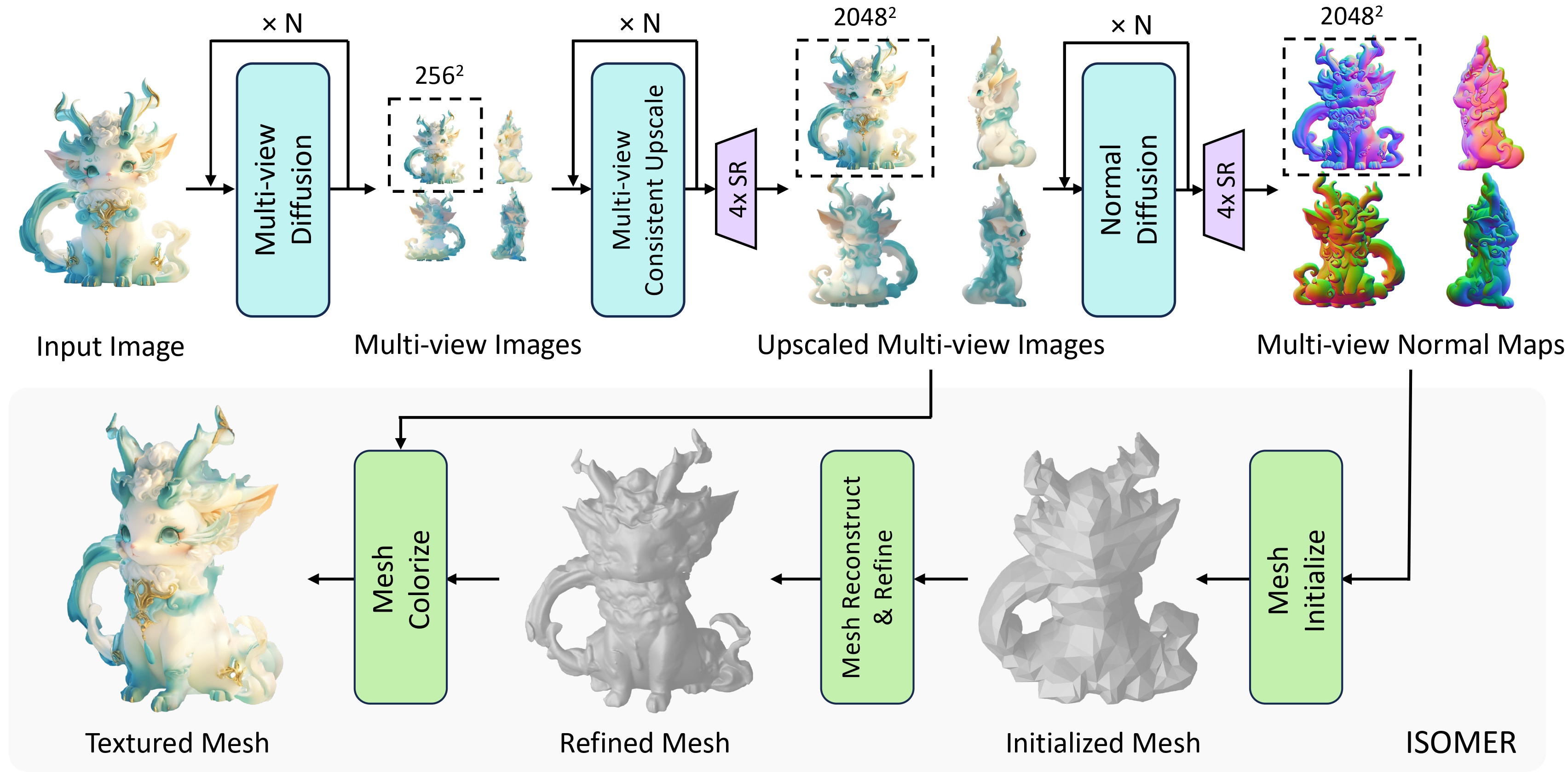
ここがスゴイ!:画像生成から3Dメッシュ化までを全自動化
これまでの技術は主に「ステップ1(多視点画像の生成)」に特化しており、最終的な3Dモデルにするには別の複雑なプログラムを組み合わせる必要がありました。
しかしUnique3Dは、高解像度の多視点画像と法線マップを生成し、さらにそれを独自の高速なシステムで「最終的な3Dメッシュ(ポリゴン)」に変換して出力するまでの全工程をワンセットに統合しました。
これにより、「画像を入れたら、高精度な3Dデータ(OBJファイルなど)が直接出てくる」という体験をついに実現しました。ゲームや映像制作の実作業で「ベースとして使える」レベルに大きく近づいた、トップクラスの実力者です。
まとめと、ビジネスへの導入について
いかがでしたでしょうか。 これら5つの技術は、「AIにいかに正確な別角度の図面を描かせるか」という壯大な課題に対して、バトンを繋ぐように進化してきました。
たった数年の間で、手作業で作っていた3Dモデルの基礎が、画像1枚から数分で生成できる時代に突入しています。ゲーム開発、メタバース、映像制作、ECサイトでの商品表示など、この技術がビジネスに革命を起こす日はもう目の前です。
「自社でも試してみたい」と思ったら?
これらの技術の多くはオープンソースとして公開されていますが、実際に自社の環境で動かすには、高性能なGPU(グラフィックボード)を搭載したハイスペックなPCや、複雑なAI環境構築の知識が不可欠です。
「試してみたいけど、専門のPC環境がない」 「自社のプロジェクトでGenerative 3Dをどう活用できるかわからない」
という壁にぶつかる方も多いでしょう。
もし、この強力な3D生成AIの力をいち早くビジネスに取り入れたいとお考えなら、ぜひ一度弊社にご相談ください!
弊社では、最新のGenerative 3D技術を活用したプロトタイプ開発や、高価なGPU環境がなくても利用できる貴社専用のAIソリューションの提案・構築をサポートいたします。
画像1枚から広がる無限の可能性を、一緒にビジネスへ実装しませんか?
「Generative AI & ML」の関連記事

1枚の写真からリアルな3Dアバターを作る。FLAME / DECA / DiffLocksを使った頭部&髪の毛生成の挑戦
写真1枚からメタバースで使えるリアルな3Dアバターを生成!最新AI「FLAME」「DECA」「DiffLocks」を組み合わせた頭部&髪の毛生成のワークフローと、独自のテクスチャ合成技術を解説します。

AIによってベトナムの雇用は減るのか?
「AIによってベトナムの雇用は減るのか?」バイタリフィ アジアCOOが語る、システム開発・オフショア業界における生成AIのリアルな影響と、次世代エンジニアに求められる「自己破壊的な好奇心」とは。

GazeboにおけるTurtleBot3を用いたLiDAR迷路探索アルゴリズムの実装と検証
ROS 2とGazeboを用いたTurtleBot3の自律走行アルゴリズム開発レポート。安価なLiDARセンサーのみで迷路走破に挑んだ実装プロセスと、ゴール目前でロボットがとった「まさかの行動」とは?