Applying Self Pre-Training Method to GNN for Quantum Chemistry
Self pre-training becomes to be commonly used method in machine learning, especially in NLP (Natural Language Processing). The most famous ones are MLM (Masked Language Modeling) and NSP (Next Sentence Prediction), which are introduced with BERT.
Some recent researches actively try to apply this idea to other domains such as Computer Vision. You can find SimCLR, MoCo and etc, which are based on Contrastive Learning.
GNN (Graph Neural Network) is another type of DNN (Deep Neural Network), which is used for various domains. In this article, I pick up an example of quantum chemistry and introduce how self pre-training can be applied to GNN and how well it works in practice.
Here is the contents of this article.
- Introduction of self pre-training
- Introduction of DimeNet, which is a GNN for quantum chemistry
- Applying self pre-training method to GNN
Introduction of self pre-training
As known well, DNN model requires a lot of data in training. Most of the computer vision models are trained with ImageNet which consists from 1.4 M ~ images and labels. It’s not so hard to imagine how painful the annotation process was.
The idea of self pre-training is introduced to solve such annotation problems. Here is the example of MLM and NSP in BERT.
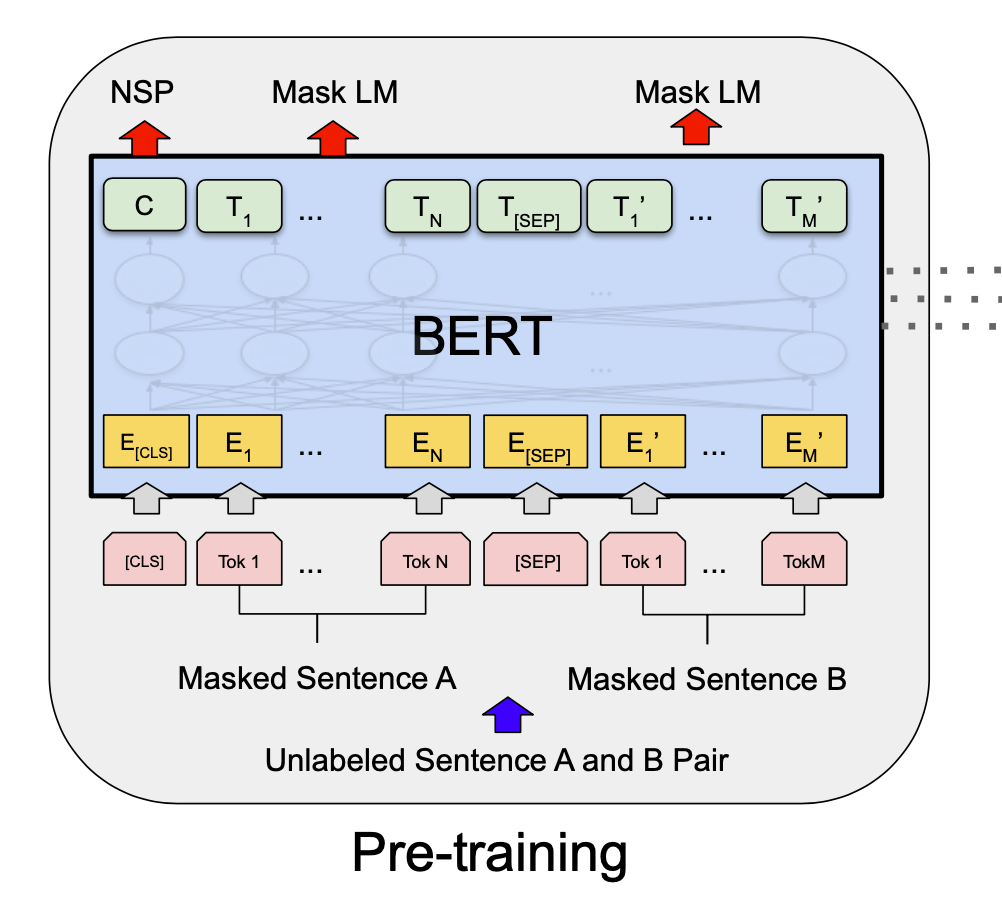
In MLM, BERT is trained to fill the randomly masked words. In NSP, BERT is trained to predict whether two sentences were originally consecutive.
Besides MLM and NSP, some other novel approaches are actively developed such as ELECTRA which uses discriminator.
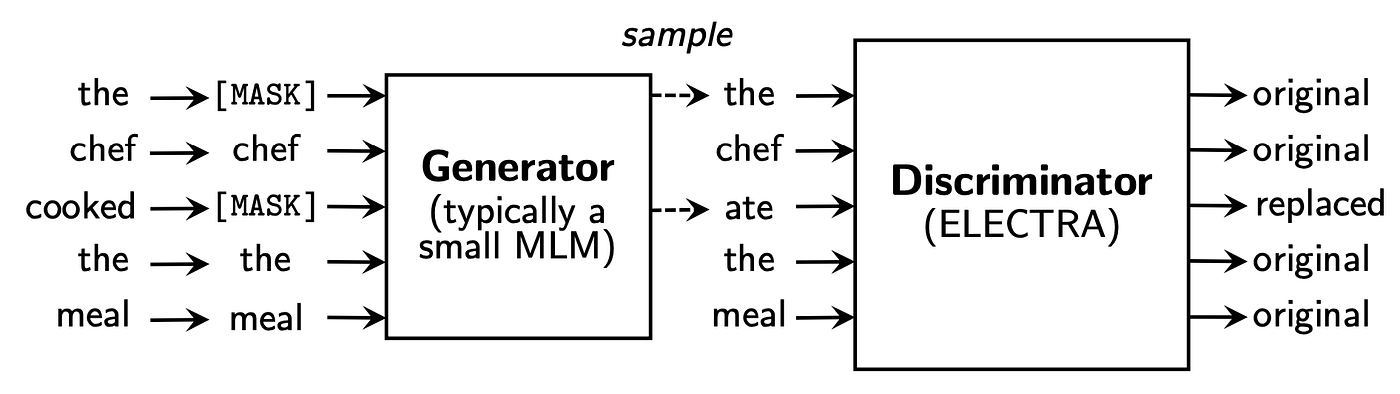
Anyway, the essential idea is same.
- Get a lot of unlabeled data.
- Manipulate them in a random way.
- Use it as an input and predict something in original state.
The pre-trained model can be fine tuned for subsequent specific tasks. Thus, it gives us the advantageous of huge dataset without labelling cost.
Introduction of DimeNet which is a GNN for quantum chemistry
In this section, I will introduce some preliminary knowledges as below, before dive into my own experiment.
- What the GNN is.
- How it is used for quantum chemistry.
- What the DimeNet is.
What the GNN is
As name shows, GNN is the Neural Network for Graph structured data.
Though there are a lot of different kinds of GNN, the common idea is almost same.
- Let the node have a state which is represented as an Embedding.
- Update the state of the nodes repeatedly with surrounding nodes along edges (Message Passing).
- Predict something for each nodes, or entire system property by gathering nodes.

How GNN is used for quantum chemistry
One of the applications of GNN is Molecule. The molecule is a set of atoms which have a 3D coordinate and atom type. The simplest modeling is supposing that the atoms as nodes, and chemical bonds as edges (but it’s not always a case). Given such information, GNN predicts a kind of molecular properties.
QM9 is a dataset of small organic molecules. It contains about 134k molecules. Each molecules have atoms with coordinates and an atom type. Given the information as an input, DFT (Density functional theory) was used to calculate some molecular properties such as energies and enthalpies as targets.
As this DFT calculation needs heavy computational resources in inference, the machine learning, data drive way, can help providing a way of faster inference which is applicable for real world usage. You can see one of such examples in Kaggle competition.
DimeNet
There are some GNN models which are proposed to solve the problems in quantum chemistry. I would like to pick up DimeNet to introduce.
The essential problem here is a multibody problem in physics, which can not be solved in an analytic way. Though DNN can represent any complex differential continuous functions, physical law still helps for better performance. Main idea is using such physical law as possible as we can, while other parts are represented by neural network.
The physical law here is the Schrödinger equation. DimeNet introduces this idea with clean architecture.
Representing distances and angles in DimeNet
The time independent Schrödinger equation on infinite spherical well can be represented by radial dependant part and angular dependant part.

A and β are constants which are incorporated to satisfy the boundary condition at r=c (c is a cutoff distance) and normalization. j is a spherical Bessel function of the first kind. Y is a spherical harmonics.
When l = m = 0, j(x) and Y(θ, φ) will be like below.
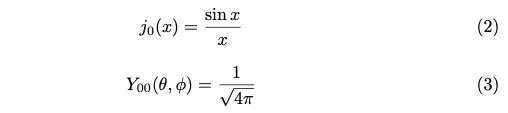
At last, the Schrödinger equation is just a sinc function of r. Its phase depends on n. When we have distances in input, it would be a good idea to feed them and map the distance into n values. This is the idea of RBF (radial basis function) in DimeNet.
As well as the case of l = m = 0, let’s take a look at some examples of j(x) and Y(θ, φ), when m = 0.

At last, the Schrödinger equation is a function depends on r and θ. It would be a good idea to feed distances and angles into it. It maps the distance and angle to n x l values. This is the idea of SBF (spherical basis function) in DimeNet.
It’s helpful for better understanding to draw one of them manually.
r = np.linspace(0, 22, 100)
theta = np.linspace(0, 2 * np.pi, 100)
rr, tt = np.meshgrid(r, theta)
# It supposes n=1 and l=0. It's ignoring normalization and border constraint.
Z = (np.sin(rr) / rr ** 2 - np.cos(rr) / rr) * (np.cos(tt))
fig = plt.figure()
ax = plt.subplot(111, projection='polar')
ax.pcolormesh(tt, rr, np.abs(Z), cmap='jet')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_theta_zero_location('N')
plt.show()

GNN architecture in DimeNet
Somehow, GNN model has to get such distances and angles. DimeNet introduces an idea of directional message passing for it.
The node in DimeNet is a pair of two atoms which have a direction. It’s so called as a directional embedding.
Message passing is done with the directional embedding (atom i and atom j) to surrounding atoms (atom k). Then, it’s possible to get an angle from atom i -> j -> k, as well as the distances between i -> j and j -> k. RBF and SBF make features and the directional embedding will be updated by them.

Applying self pre-training method to GNN
The DimeNet originally performs really well, though it’s a little bit slow.
Self pre-training can give us further boost. Further more, once we get the pre-trained weight, the subsequent training can converge in shorter time.
Description about self pre-training
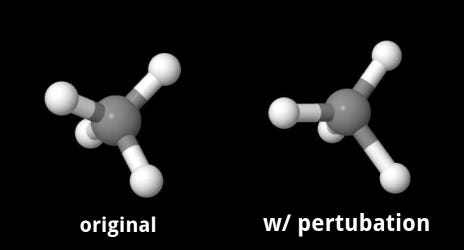
The idea of self pre-training here is simple and straight forward. As the input is 3D coordinates and atom types, I can manipulate both or either of them. At this time, I use 3D coordinates.
If the 3D coordinate of atoms in a molecule are moved a little bit, GNN model will be able to restore the original position by learning physical law behind it.
Restored well or not can be evaluated by comparing the original coords and moved coords. I compare pairwise distances, D_original and D_moved, in a molecule, as it’s necessary to consider translational and rotational invariants.
This task can be summarized as below.
- Give atom’s coords perturbation randomly.
- Train model to minimize the differences of pairwise distances between original and moved.
Result
There are 12 different target properties in QM9. I used μ (Dipole moment) as a target for this experiment.
| No. | Question | Answer |
|---|---|---|
| 1 | What is Communism? | Communism is the doctrine of the conditions of the liberation of the proletariat. |
| 2 | What is the proletariat? | The proletariat is that class in society which lives entirely from the sale of its labor and does not draw profit from any kind of capital; whose weal and woe, whose life and death, whose sole existence depends on the demand for labor... |
| 3 | Proletarians, then, have not always existed? | No. There have always been poor and working classes; and the working class have mostly been poor. But there have not always been workers and poor people living under conditions as they are today... |
| 4 | How did the proletariat originate? | The Proletariat originated in the industrial revolution, which took place in England in the last half of the last (18th) century, and which has since then been repeated in all the civilized countries of the world. |
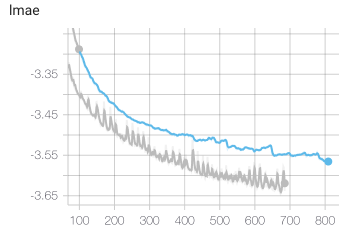
Table 1: MAE w/ or w/o self pre-training. EMA model is used for both.
As shown on table 1, DimeNet achieves 0.0285 without pre-training. It’s almost same with the score reported in original paper, and it’s nearly SOTA up to now.
The DimeNet with self pre-training method outperforms the original result. Furthermore, it was achieved in much less epochs.
All of the code is available in my github repo.
Conclusion
I have shown that the self pre-training way works pretty well in GNN as well as in NLP, though the method is quite simple.
Because of my limited time, I have tested only one target property at this time. However, it would be worth to try other 11 more target properties.
I realize that the situation in molecule is not always same with the images and texts. Images and texts overflows in internet, while the coordinates of molecule must be made with some cost. However, we can see some similar dataset such as PDB, which is the massive dataset of protein structure collected in vitro. In such areas, the way of self pre-training will be also applicable. I look forward to see great results in such areas too.
Struggling to turn ideas into reality? With a proven track record of over 1,000 clients, our agile and flexible team will accelerate your business growth.
Book a Free ConsultationMore on "Generative AI & ML"

3D Avatar from One Photo with FLAME, DECA and DiffLocks
From a single face photo, we tested a workflow for creating a realistic 3D head and natural-looking hair using FLAME, DECA and DiffLocks. This article covers the process, results, texture issues, hair generation challenges and license notes.

Will AI Reduce Employment in Vietnam?
Will AI reduce jobs in Vietnam? VFA's COO discusses the real impact of generative AI on offshore development and the "self-destructive curiosity" needed for the next era.

AI Economist: Reinforcement Learning in Economics
Experimenting with the AI Economist API to simulate free markets and communism using Reinforcement Learning (RL) agents.